![CC-VQA [循环一致性]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/CCVQA-2.png)
CC-VQA [循环一致性]
Paper Download Address
已有的工作研究了VQA模型对图像中有意义的语义变化的鲁棒性和敏感性,改变答案分布和对图像攻击,但是没有对问题语法变化的研究,问题形式变化对VQA model的能力(VQA系统是否真的理解了问题)以及应用程序(用户会用不同的语言形式来提问)角度来说都是非常重要的,但是目前SOTA模型对问题语言的变化是十分脆弱的
作者提出了一个循环一致性(cycle consistency)的框架,训练模型在回答问题的基础上还要生成形式不同但是语义相同的问题变体,要求生成的问题预测的答案与原始问题的ground truth答案相匹配
这个训练框架有两个优点,一是提高了模型在测试集问题形式变化时的泛化的能力,二是模型可学习的bias减少了,因为一个要同时完成问题生成和问题回答任务的模型不太容易利用语言先验以及走捷径
为了能够定量评估VQA模型在输入问题中的语言变异的鲁棒性和一致性,作者收集了一个大规模数据集VQA-Rephrasings,并在该数据集上测试了SOTA模型,实现表明VQA模型对问题语言表示变化的脆弱性,这说明现有的VQA模型并不能充分理解语言,用 ...
![DFAF [动态模内模间注意流]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/DFAF-1.png)
DFAF [动态模内模间注意流]
Paper Download Address
VQA模型性能的提升得益于三个方面,一是更好的视觉和语言特征表示,二是注意力机制,三是更好的多模态融合方法
目前的VQA模型大多在学习视觉和语言特征之间的跨模态关系(inter-modality relations),Bilinear feature fusion主要通过特征的外积来获取语言和视觉模式之间的高阶关系,Co-attention和bilinear attentionbasedapproaches通过学习词区域对(word-region pairs)之间的跨模态关系来完成VQA任务
此外也有学习模态内部关系(intra-modality relations)的方法,Hu et al提出探索模内对象-对象关系,以提高目标检测精度,Yao et al学习模内对象-对象关系,以提高图像字幕性能,BERT采用自注意机制对模内词关系进行建模,得到了SOTA的word embedding,
在解决VQA问题的框架中从未同时研究过模内关系和跨模关系,作者认为被大多数VQA系统忽略的模内关系是跨模关系的补充,每个图像区域不仅要从问题中的关联词/短 ...

Count模块源码解读
Code Download Address
Paper Record
计数的基本方法是确定边的数量,通过子图完全图边和点的关系来计算点数,最后得到答案
top n bounding box首先处理出处理出top n的注意力权重和对应的bounding box
123456def filter_most_important(self, n, boxes, attention): """ Only keep top-n object proposals, scored by attention weight """ attention, idx = attention.topk(n, dim=1, sorted=False) idx = idx.unsqueeze(dim=1).expand(boxes.size(0), boxes.size(1), idx.size(1)) boxes = boxes.gather(2, idx) return boxes, attention
boxes的sha ...
![Learning To Count [VQA计数]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/learningToCount-0.png)
Learning To Count [VQA计数]
Paper Download Address
想要统计图中有几只猫通常需要这样几个步骤:理解实例的视觉表现,在图中找到实例以及计数
这在VQA中是一个常见的Task,然而目前的VQA系统在数据集bias之外的情况很难回答计数问题,主要原因是广泛使用的软注意力机制以及VQA中的计数并不像标准计数对计数目标有GT标定
模型需要能够对大量对象进行计数,并且在理想情况下,在非计数问题上的性能不受到损害,因此非常具有挑战性
为了简化这个task,作者采用object proposals,即将目标检测得到的bounding box和对应的对象特征作为输入而非从pixel层面学习。在复杂的场景中,通常会遇到重复计算重叠对象的问题,这是一个存在于许多自然图像中的问题,它会导致在真实场景中不准确的计数
文章的主要贡献是提出了一个可微的神经网络组件来完成计数,该组件与注意机制一起使用,避免了软注意的基本限制,同时产生强大的计数功能,实验表明,使用计数组件的相对简单的基线模型优于所有以前的模型,而不会降低其他类别的性能
RELATED WORKgreedy non-maximum suppression ...
![Where To Look [注意力机制]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/whereToLook-2.png)
Where To Look [注意力机制]
Paper Download Address
这篇文章主要致力于解决VQA和其它一些视觉推理问题中的一个核心任务:knowing where to look
如图所示,若红绿灯能够成功被定位,则可以轻易回答问题”What color is the walk light”,如何能够定位到雨伞,则有利于回答”Is it raining”,模型需要学习到被期待的答案的类型,以及做出回答需要基于图片的哪部分
where to look的实现是具有挑战性的,有些问答需要利用全图,而有些回答则需要关注特定的区域,文章中忽略需要额外知识辅助回答和需要推理回答的问题(比如图中男女在约会么)
作者的key idea是学习一个非线性映射,将图片和问题投射到相同的latent space来确定它们之间的关联,然后对相关区域和QA对的匹配度打分,latent space和打分函数由用QA对监督的margin-based loss来共同学习
文章主要的贡献为:
提出了一个图像区域选择机制,学习识别问题相关的图像区域
提出了一个采用margin-based loss的VQA多选题的学习框架,明显优于base ...
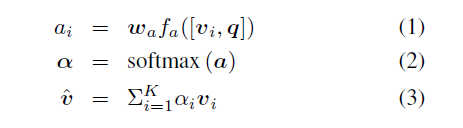
Tips and Tricks for Visual Question Answering
Paper Download Address
这篇文章提出了一个相对简单的VQA模型,达到了SOTA的效果,文章的核心目的是分享一个成功的VQA模型的细节
model首先得到问题和图片的联合嵌入(joint embedding),随后是针对一组候选答案的多标签分类器,这种通用方法是现在很多VQA模型的基础,模型的细节对于获得高质量的结果至关重要
同时作者在模型上采用了一些关键的技术创新,极大提高了模型的表现,作者在探索模型空间结构和超参数上进行了大量的实验,以确定每个组件的重要性
主要发现概括如下
—— 使用sigmoid输出,允许每个问题有多个正确答案,而不是一个常见的单标签softmax
—— 使用软分数作为GT目标,使得task为候选答案分数的回归,而不是传统的分类
—— 对所有非线性层使用gated tanh激活函数
—— 采用bottom-up注意力得到的图片特征,自底向上注意力提供的是特定区域的特征,而非CNN传统的网格特征图
—— 使用预先训练好的候选答案表示来初始化输出层的权重
—— 在随机梯度下降的训练过程中对训练数据采用较大的mini-batches,以及智能打乱( ...
![EST-VQA [双语文本VQA]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/ESTVQA-1.png)
EST-VQA [双语文本VQA]
Paper Download Address
对数据集中的巧合相关性的学习使得VQA系统难以泛化,巧合相关性在数据集中并不稳定,当测试集中的分布与训练集不同时,基于巧合相关性所学习到的东西就不再work
泛化VQA存在的一个潜在问题就是无法判断正确答案是否由正确的理由产生,通过推理得到的答案和通过巧合相关性得到的答案表面上是完全一致的
文章中提出一种度量VQA性能的方法,它通过要求算法证明其推理的合理性来鼓励泛化
之前也有相关工作研究过推理过程,但是因为提供理由的形式是有限的而饱受困扰,文章中的方法是提供一个简单的指示,说明它的答案是基于图像的哪个区域,若VQA系统提供了正确的答案和正确的图像区域,则说明其推理过程是正确的
作者在Scene Text VQA上做测试,选择这种测试集的原因是大部分VQA model在Text VQA数据集上表现不佳,但是图片中的文本对图片的理解往往是很有指示意义的,而且文本VQA问题通常不太容易通过利用数据中的巧合相关性来解决
同时,因为文本VQA图像中出现的文本范围十分广泛,因此基于分类的方法很容易过拟合,需要开发替代方法,并且这些方法可以推广到其它 ...
Squeeze-and-Excitation Networks
Paper Download Address
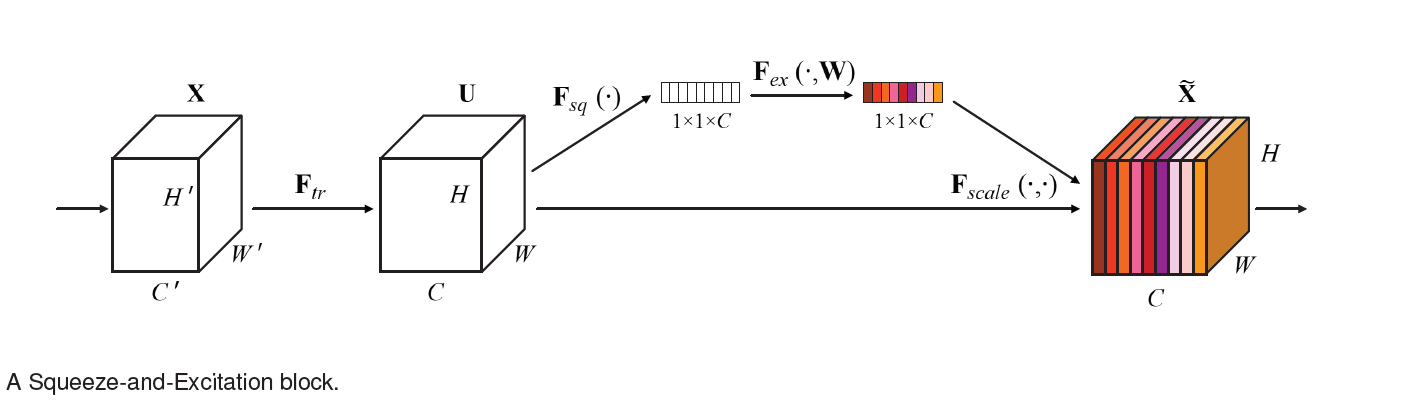
在卷积网络的每一层,一些卷积核沿着输入通道方向表示相邻特征模式,在局部感受野(local receptive fields)的范围内融合空间及channel-wise特征信息。通过交错的组合卷积,下采样,非线性层等构建网络,CNN可以达到理论上的全局感受野(global theoretical receptive fields),以捕获图像的特征来进行图像的描述。最近的研究表明,将集成学习机制整合到CNN中可以提高网络的表示能力,Inception结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益,还有进一步的工作是寻求更好地模拟空间依赖性,并将空间注意纳入网络的结构
文章跟以往的网络结构均不同,研究的是通道(channel)之间的关系。文章中提出了一种机制,允许网络执行特征重新标定,通过这种机制,网络可以学会使用全局信息,有选择地强调信息特征,抑制不太有用的特征
给定输入X,通过一系列的卷积操作变成特征通道数为C的U,执行Squeeze操作,顺着空间维度进行特征压缩,将每个二维的特征通道变为一个实数,这个实数在某种程度上具 ...

BUTD注意力机制
Paper Download Address
在图像字幕和VQA中使用的大多数传统视觉注意机制都是自顶而下的,这些机制通常被训练成有选择地关注CNN的一个或多个层的输出,然而这种方法很少确定图像的关注区域
传统的CNN网络在引入注意力机制的时候,图像区域会分成大小均一的网格(左图),为了生成更像人类的字幕和问题答案,要将注意力自然地放在物体和其他突出的图像区域上,因此文章中提出的注意力机制是对象层面的(右图)
文章提出了一种结合自顶向下和自底向上的注意力机制,自底向上采用Faster R-CNN模型处理显著图像区域,每个区域由一个池化卷积特征向量表示,自顶向下采用task-specific来预测注意力区域,将其特征作为所有区域的图像特征的权重
相关工作在VQA和图像字幕领域产生了大量基于注意力机制的深度神经网络,这些模型可以被归类为自顶向下的方法,注意力机制被应用于CNN的一个或多个层的输出。然而,确定图像区域的最佳数目总是需要在不同细节层次之间进行权衡,此外,与图像内容相关的区域的任意定位可能会导致检测到与区域不一致的物体,且将同一物体相关的视觉概念结合起来会变得更加困难
相对而来 ...
![VC R-CNN [将常识引入特征]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/VCRCNN-2.png)
VC R-CNN [将常识引入特征]
Paper Download Address
现今的计算机视觉系统擅于告诉我们”什么”,”哪里”,但并不擅长告诉我们”为什么”,这个”为什么”指的就是视觉原因,缺乏常识很容易导致机器学习中的认知误差,比如和leg区域相比,有更多的person区域和ski单词一同出现,那么视觉注意力会更多地放在人身上,但如果我们拥有”常识性”的特征,看到ski的时候我们就会把注意力集中到脚上
常识并不总是包含在语言中的(因为有reporting bias),比如我们会看到”人在路上走”,但应该很少见到”人用脚走路”。NLP中词X可以通过预测上下文中的Y来学习,但是这种做法很难迁移到图像中,因为图像中对象同现的显式原因无法被观察到,那么导致X和Y同现的真正常识会被observational bias混淆,比如如果键盘和鼠标总是被观察到在桌子上,那么得到的常识可能是键盘和鼠标是桌子的一部分而非电脑
文章利用MS-COCO数据集中的标注信息,计算Association P(Y|X)和Intervention P(Y|do(X))之间的区别,这里可以简单地理解为1.从别的图片”bollow”一个对象Z;2.将 ...
![SQulNTing [子问题一致性]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/SQulNTing-1.png)
SQulNTing [子问题一致性]
Paper Download Address
VQA问题要求模型在多个抽象层面进行推理,比如要回答问题”这个香蕉熟到能吃的地步了么”,VQA model需要检测香蕉并且提取它的相关属性比如大小和颜色。抽象概念是复杂,多细节层次的。
文章中将问题分为感知和推理两类,感知问题只要求对对象确认存在,查询对象的物理属性和判断对象之间的空间关系,比如”图中香蕉是什么颜色的”或者”这个人的左边的是什么”,推理问题则需要结合视觉感知,逻辑和先验知识来完成,比如”这个香蕉熟到能吃的地步了么”
将问题划分为感知和推理可以更好地评估模型的视觉感知和高级推理能力,作者认为,将感知问题作为推理问题的子任务是有帮助的。通过阐述这样的子任务,可以检测模型是通过合理推断还是通过数据集中的bias和捷径来得到答案。就比如,我们需要留意一下模型的推理能力当其对于香蕉的颜色答案为黄,但对于香蕉能否食用答案是否的时候。高水平推理任务与低水平感知任务之间的不一致表明model还没有有效地学习如何回答推理问题。这些子问题可以用来对任何VQA模型评估而不仅是那些被用来提供理由的模型
随着推理问题的复杂化,目前使用的方法实现良好的 ...
![GQA-OOD [低频样本处理]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/GQAOOD-1.png)
GQA-OOD [低频样本处理]
Paper Download Address
玫瑰是红色的,紫罗兰是蓝色的,但是,VQA系统理应期待他们是这样的么?
目前多数的VQA数据集仍然非常的不平衡,大量常用的表述比如红玫瑰,与上下文无关的表述比如城市中的斑马,这些表述导致模型过分依赖于biases,缺乏一般化的能力。尽管对这个问题有普遍的共识,对误差分布的系统性评估仍然非常稀缺。整体正确率依然是主流,甚至唯一的评判依据,虽然这是不合理的。
现在对于模型的评判有这些问题:误差分布是什么样的?正确的预测是因为推理还是因为偏见?在低频样本和高频样本上的正确率如何?如何在分布之外(OOD)验证模型?
文章提出了一种新的标准,这个标准包含
一个重新组合的GQA数据集,在验证集和测试集中引入分布变换
一系列评估方法
新的评价图来说明VQA在不同操作点上的推理行为
选择GQA数据集是因为其问题组结构能够捕捉biases,可以以此来选择具有较强偏见的组并创建分布转换,为每一个问题添加约束
作者用这个标准做了大量的实验发现许多SOTA VQA模型都不能胜任解决不常见问题的工作,同时在VQA降低偏见的方法上得到同样的结论。
仅在高频样本上 ...

为VQA生成原因
Paper Download Address
想要在VQA任务中有突出的表现,model必须理解问题并找到问题相关答案的能力,有个严肃的问题是这些model在预测答案的时候到底能够理解image,question和answer到一个什么程度,它们是否只是利用了问题,图片或者答案中的biases
衡量模型对三个方面(questions, images, answers)的理解能力并不是一个主流工作,之前相关工作有对word进行微扰,检查视觉热力图等,文章希望做的是对三个方面做一个联合,同时测试模型语言和视觉模块
为了完成这一点,文章为VQA系统提出了一个novel task,不仅要理解问题(linguistic modality),理解图片(visual modality),同时也要为预测的答案提供理由,指出其和图片以及问题的关系
作者采用VCR(Visual Commonsense Reasoning)数据集,该数据集中包含图片,问题,对应的四个候选答案,和四个原因选项,作者用VQA系统选择答案,然后对答案生成原因,对比真实原因来评估model的综合理解能力
作者用这个方法测试了VCR ...
通过分解语言表征来克服VQA中的语言先验
Paper Download Address
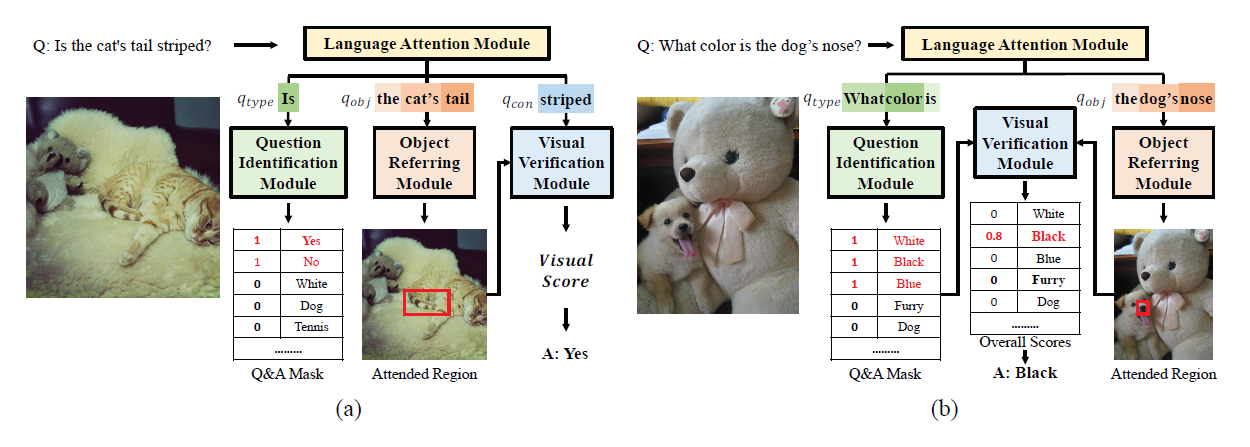
目前多数VQA model中存在语言先验(Language Priors)问题,比如对于颜色会快速回答”white”,对于运动会快速回答”tennis”,对于”is there a”开头的问题会快速回答”yes”,这些模型并不能真正辨别问题中信息的不同之处,他们只是利用答案和询问词(interrogative words)的同现性来得到答案
尽管有些模型采用了问题注意力机制,将关键词和视觉信息结合,但是它们并没有消除interrogative words的影响,因此仍存在language prior
[1]的研究中,为了消除language piror,用多个手工设计的模块来处理问题中不同的信息,他们用一个问题分类器将问题划分为yes/no类别和非yes/no类别,用一种基于词性的概念抽取器来提取yes/no问题中的概念,以及答案聚类预测因子确定非yes/no问题的答案类型
[1] Agrawal, A.; Batra, D.; Parikh, D.; and Kembhavi, A. 2018. Dont just assume; loo ...
![CSS-VQA [反事实]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/CSSVQA-2.png)
CSS-VQA [反事实]
Paper Download Address
由于数据集的问题,目前很多VQA模型仍然过于依赖language biases,比如一个对于”how many X”问题只会回答2的模型可以依然得到比较满意的表现。因此有了新的判断指标VQA-CP (VQA under Changing Priors),这个数据集中训练集和测试集的QA分布不同,导致许多SOTA的VQA model在这个数据集中准确率都有显著的下降
当下流行一些基于集成(ensemble-based)的方法来减轻bias的影响,他们用question-only model来调整VQA model的训练过程,这些方法大致可以分为两类:
1.adversary-based:用对抗的方法训练两个model,最小化VQA model的损失的同时最大化question-only model的损失,两个model共享同一个question encoder,目标是学习一个bias-neutral的问题表示。然而,因为训练过程不稳定,因此产生了巨大的噪声
2.fusion-based:最后将两个model的答案分布结合起来,设计理念是让VQ ...
![VQA:数据集,算法和未来挑战 [综述]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/VQA-1.png)
VQA:数据集,算法和未来挑战 [综述]
Paper Download Address
VQA(Visual Question Answering)是一个计算机视觉task,给定一个图片相关的问题和对应的图片,通过程序推断出答案
要求解决的问题是任意的,并且包含了诸多计算机视觉当中的子问题,比如
目标识别 (图中的物体是什么)
目标检测 (图中有猫么)
属性分类 (图中的猫是什么颜色的)
场景分类 (图中的天气是晴天么)
计数 (图中有几只猫)
当然除了这些,还有更多复杂的问题,比如目标的空间关系问题 (在沙发和猫之间的物体是什么),常识推理问题 (图中的女孩为什么哭)
这是一篇2017年发表在Computer Vision and Image Understanding关于VQA的综述,文章内容包含以下几块
VQA与一些视觉和语言问题的对比
VQA当前可用的数据集以及优缺点
讨论VQA的评价指标
分析VQA已有的算法
讨论VQA未来的发展
VQA与其它视觉与语言任务的对比(这部分大致是我对这个章节的翻译,了解一下背景)
VQA的最终目标是从图片中获取问题相关的信息,根据问题,任务的范围可以从微小细节的检测到整张图片场 ...
基于样例的相机行为控制器
背景相机规划一直是虚拟现实领域一个活跃的讨论话题但相机行为(轨迹)的计算问题却甚少有人关注
已有用路径或者运动规划来指导相机轨迹的研究,主要受机器人学文献的启发
但大多数相机规划方法的关键实际上是描述何为好的运动(轨迹)
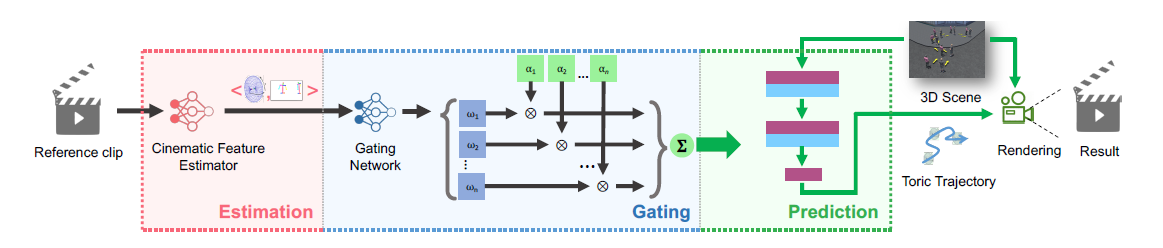
文章更倾向于从真实的电影片段中提取相机行为,文章在有限行为集上训练的深度学习网络,能够从真实的电影序列中提取相机行为,并利用对相机行为集合的先验学习将其重新定位到虚拟环境中
文章提出:基于样例的相机行为控制器
1.能够处理比单目标摄像更一般的情况(特别是电影中常见的双人交互)
2.通过从合成和真实电影剪辑中获得的一系列不同相机行为进行训练
3.自动从用户选择的电影片段中提取相机行为,投射到虚拟环境中
系统架构(1)a cinematic feature estimator
从电影剪辑中提取相关特征作为输入,在电影特征空间进行表示(输出)
(2)a gating network
通过low dimensional manifold学习,充当选择器
输入电影特征空间 (a path in the cinematic feature space)
输出为一系列相机行为,作为 ...

Wasserstein GAN
Wasserstein GAN希望采用Earth Mover Distance来取代JS-divergence,以解决GAN训练中梯度弥散和梯度不稳定的问题
首先是梯度弥散问题,生成器梯度弥散的原因是过分优秀的判别器,判别器越能准确的分辨$G$和$Data$,生成器梯度消失就越严重
对于最优参数的判别器,生成器Loss为
$C(G)=-log4+2D_{JS}(p_{data}||p_G)$
上式推导戳此处
最小化Loss就是最小化JS散度,具体在训练中就是尽量将$P_G$拉向$P_{data}$
JS divergence的问题就在于生成的数据和真实数据往往没有任何重叠,一是Data本质的问题,image在高维空间中的分布是一个低维的manifold,两者很难有overlap,其次在具体实现中Sampling使得overlap的概率更低
观察JS散度的表达式
$D_{JS}(P||Q)=\frac{1}{2}D_{KL}(P(x)||\frac{P(x)+Q(x)}{2})+\frac{1}{2}D_{KL}(Q(x)||\frac{P(x)+Q(x)}{2})$
$D_{KL}(P ...
fGAN--任意散度GAN
fGAN的基本想法就是希望用不同的散度来取代JS散度
使得任何divergence都可以应用到GAN的框架中
f-divergence :$D_f(P||Q) = \int_{x} q(x)f(\frac{p(x)}{q(x)})dx$
$f$函数需满足当$x=1$时 $f(x)=0$ 且$f$是$convex$
这个式子可以衡量分布P和Q的差异
若P分布和Q分布相同,则$D_f(P||Q) = \int_{x} f(1)dx=0$
当P分布与Q分布不同时,$D_f(P||Q) = \int_{x} q(x)f(\frac{p(x)}{q(x)})dx \ge f(\in_{x}q(x)\frac{p(x)}{q(x)}) =f(1) = 0$
(这里的积分大于等于是因为$f$是$convex$)
当$f(x)=xlogx$时
$D_f(P||Q)=\int_{x} \frac{p(x)}{q(x)} log(\frac{p(x)}{q(x)})=\int_{x} p(x)log(\frac{p(x)}{q(x)})=D_{KL}(P||Q)$
当$f(x)=-logx$时
$D_f( ...
CycleGAN的隐写术
(CycleGAN的介绍戳此处)
在CycleGAN的训练过程中
研究者发现,一张图片从Domain X到Domain Y的过程中可能会丢失了细节
但是令人惊讶的是,这张缺失细节的图从Domain Y映射回Domain X的时候这些细节又会被补全
也就是说CycleGAN在做Domain X到Domain Y的转化的时候隐藏了一些细节,使得我们肉眼无法观察到,但是其本身可以通过某些手段将这些记录的细节还原
用自适应直方图均衡化的手段可以观察到,CycleGAN学会了用低振幅高频信号的形式来隐藏原始图像中的细节信息,这种信号看起来几乎像是噪声,而利用这些信息,G可以再现原始图像,使得循环一致性的要求被满足
CycleGAN这种编码信息的特性很容易使得其遭受对抗性的攻击,攻击者可以通过干扰选定的原图像,使得Generator产生他们所选择的图像
文章作者认为CycleGAN模型的这种问题来自于循环一致性损失和Domain之间的熵差,因此改进的手段有修改循环一致性和添加额外的隐藏变量来人为地增加一个Domain的熵
比如在Cycle的时候引入噪声干扰信息编码等
不得不说CycleGAN利用信 ...


