CC-VQA [循环一致性]
已有的工作研究了VQA模型对图像中有意义的语义变化的鲁棒性和敏感性,改变答案分布和对图像攻击,但是没有对问题语法变化的研究,问题形式变化对VQA model的能力(VQA系统是否真的理解了问题)以及应用程序(用户会用不同的语言形式来提问)角度来说都是非常重要的,但是目前SOTA模型对问题语言的变化是十分脆弱的

作者提出了一个循环一致性(cycle consistency)的框架,训练模型在回答问题的基础上还要生成形式不同但是语义相同的问题变体,要求生成的问题预测的答案与原始问题的ground truth答案相匹配
这个训练框架有两个优点,一是提高了模型在测试集问题形式变化时的泛化的能力,二是模型可学习的bias减少了,因为一个要同时完成问题生成和问题回答任务的模型不太容易利用语言先验以及走捷径
为了能够定量评估VQA模型在输入问题中的语言变异的鲁棒性和一致性,作者收集了一个大规模数据集VQA-Rephrasings,并在该数据集上测试了SOTA模型,实现表明VQA模型对问题语言表示变化的脆弱性,这说明现有的VQA模型并不能充分理解语言,用CC-VQA方法训练能在这方面有所提升
文章的贡献如下:
提出基于循环一致性的训练方法,使得VQA模型更加鲁棒
提出VQA-Rephrasings数据集
用CC-VQA训练方法训练SOTA模型,在VQA-Rephrasings上有所提升
Related Work
(Visual) Question Generation
基于图像生成问题的方法在Towards automatic generation of question answer pairs from images中被引入,Generating natural questions about an image中提出了一个超大的VQG数据集来评估模型的问题生成能力,IVQA提出了一种基于变分LSTM的模型,经过强化学习的训练,为图像生成特定答案的问题,Dual Task通过将问题生成和问答问题作为双重任务来生成针对特定问题种类的答案
文中的方法并不局限于生成特定类型的问题,VQG组件的目标是自动生成问题重表述,从而使VQA模型对语言变化更具鲁棒性
Cycle-Consistent Learning
用循环一致性的方法规则化模型的训练目标跟踪,机器翻译和文本问答中都有采用,循环一致性在涉及单一模态(纯文本或纯图像)的领域中得到了广泛的应用,但在像VQA这样的多模态任务环境中还没有进行过研究
Approach
循环一致性方法如图所示
先用VQA model对(V,Q)产生A’,然后用VQG对(A’,V)产生Q’,生成Q’的过程如图(b)所示,随后再用VQA对(V,Q’)得到A’’
假设生成的问题是原问题的有效改写,那么一个健壮的VQA模型应该用与原问题相同的答案来回答这个改写问题,具体实现时,有很多问题阻碍了VQA系统中循环一致性的实施,以下会讨论这些问题和处理这些问题的关键组件
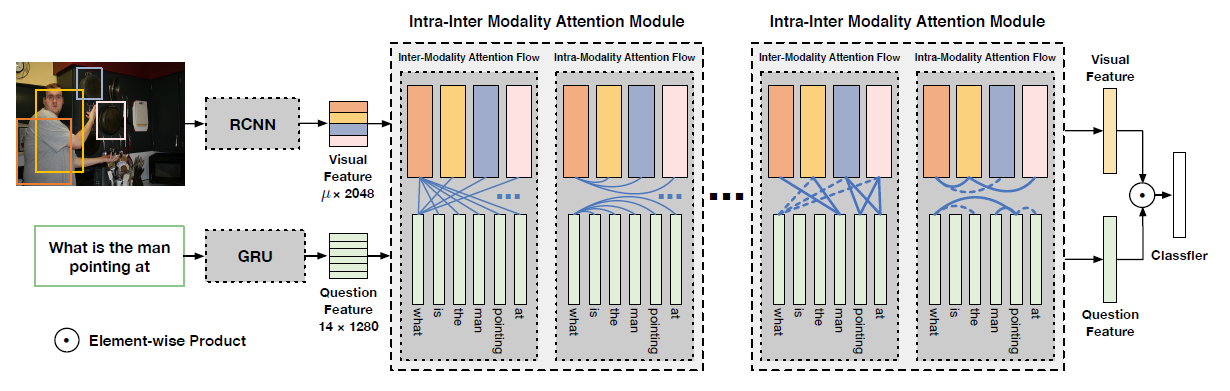
Question Generation Module
在处理单模态的循环一致性模型中,需要在具有大致相似信息内容的相同模态的不同domain间学习转换,但是像VQG这样的多模态转换中,学习从低信息模态(如回答)到高信息模态(问题)的转换需要额外的监督,作者以注意力的形式对VQG提供额外的监督,引导VQG的注意力到VQA回答问题的图像区域,这使得模型能够从”Yes”这样的答案中产生与最初的问题更相似的问题
问题生成模块由两个线性编码器组成,将VQA模型得到的图像特征和答案空间上的分布变换到更低维的特征向量。将这些特征向量与附加的噪声相加,然后通过一个LSTM,该LSTM经过训练来重构原始问题,并通过teacher forcing最小化负对数似然来优化
文章的做法不传递表示得到的答案的onehot vector,或者将得到的答案嵌入到问题生成中,而是对答案的分布进行预测,这使得问题生成模块能够学习将模型的置信度映射到生成的问题答案上
Q-consistency指通过VQG产生的问题Q’和原始VQA问题的Q的一致性损失$L_G(Q,Q’)$,A-consistency指生成问题产生的答案A’’和GT答案A的一致性损失$L_{cycle}(A,A’’)$
总的Loss可以表示为
$L_F(A,A’)$和$L_{cycle}(A,A’’)$是交叉熵损失,$L_G(Q,Q’)$是sequence generation loss,两个$\lambda$是可调的超参数
Gating Mechanism
作者提出的循环一致训练方案的一个假设是,所生成的问题在语义和句法上总是正确的,然而实际上这不会总是对的,不加过滤地用答案生成的问题会导致失败,和VQA模块一样,VQG模块也不完善,因此,问题生成器生成的问题并不是都与图像、答案和原问题相一致
为了克服这个问题,作者提出了一个门控机制,它在将VQG模型生成的不合适的问题传递给VQA模型之前自动过滤这些问题,以达到A-consistency,只保留那些VQA模型F能够正确回答的问题,或者与原始问题编码的余弦相似度大于临界值的问题
Late Activation
设计循环一致模型的一个关键部分是防止模式崩溃,在像VQA这样复杂的环境中,学习循环一致的模型需要一个精心选择的训练方案,由于循环一致的模型有几个相互连接的学习不同转换的子网络,因此确保每个子网络协调工作非常重要,如果VQA模型F和VQG模型G是联合训练的,并且在训练的早期阶段执行一致性,那么这两个模型都可能通过产生不希望的输出来”欺骗”
作者通过在训练的后期激活循环一致性来克服这个问题,以确保VQA和VQG模型都得到了足够的培训,以产生合理的输出,具体地说,在一定的迭代次数之后才使循环一致性相关的loss有效
问题生成模块、门控机制和延迟激活的设计选择对于有效训练模型至关重要,为了增强VQA模型对所有生成的变化的鲁棒性,所以回答原始问题的VQA模型与生成的重新表述之间的权重是共享的,VQA中循环一致性的公式也可以被认为是一种在线数据扩充技术,其中模型是针对同一个问题的几个生成的表述进行训练的,因此在推理过程中对这些变化更加稳健,这种稳健性也赋予了VQA模型更好地预测自身失败的能力
VQA-Rephrasings Dataset
VQA-Rephrasings是能够评估VQA系统对于问题语法变化的鲁棒性的数据集,采用VQA2.0的一个split作为基础,作者采用人工标注的方式对每个问题收集了三个rephrasings
人工标注分为两个阶段:
在第一阶段,研究人员将原始问题和相应的真实答案灌输给人们,并要求他们对问题进行rephrasing,保证新问题的回答与原始答案保持一致。为了确保第一阶段的rephrasings在语法上正确并在语义上与原始问题一致,需要在下一阶段过滤收集到的响应
第二个阶段给定标注人员原始问题和rephrasing,要求对rephrasing标注无效mask当其:(a)和原始问题的答案不一样;(b)出现语法错误
对于一个VQA模型来说,要在同一问题的不同表述之间保持一致,所有表述的答案应该是相同的,作者用共识分数$CS(k)$来衡量这一点。首先对大小为k的子集进行抽样,共识分数$CS(k)$定义为所有答案都正确的子集数与大小为k的子集总数的比值
而问题的答案是否正确通过S(Q)来衡量,相关文献
$^nC_k$是大小为$k$的抽样子集的数量,要使一组问题$Q$在$k$处达到非零的共识分,模型必须在一组问题$Q$中至少正确回答k个问题,当$k=|Q|$,模型需要回答对所有形式的问题,显然k越大,模型对问题的语言变化更稳健
Experiments
SOTA模型加上CC模块在VQA-Rephrasings上的测试
消融实验
可视化对比:
第一行:Pythia
第二行:Pythia + CC
VQA-Rephrasings的数据example,更多baseline+cc的可视化比较,VQG module生成的问题example可查阅paper附录
![支付宝]() 支付宝
支付宝