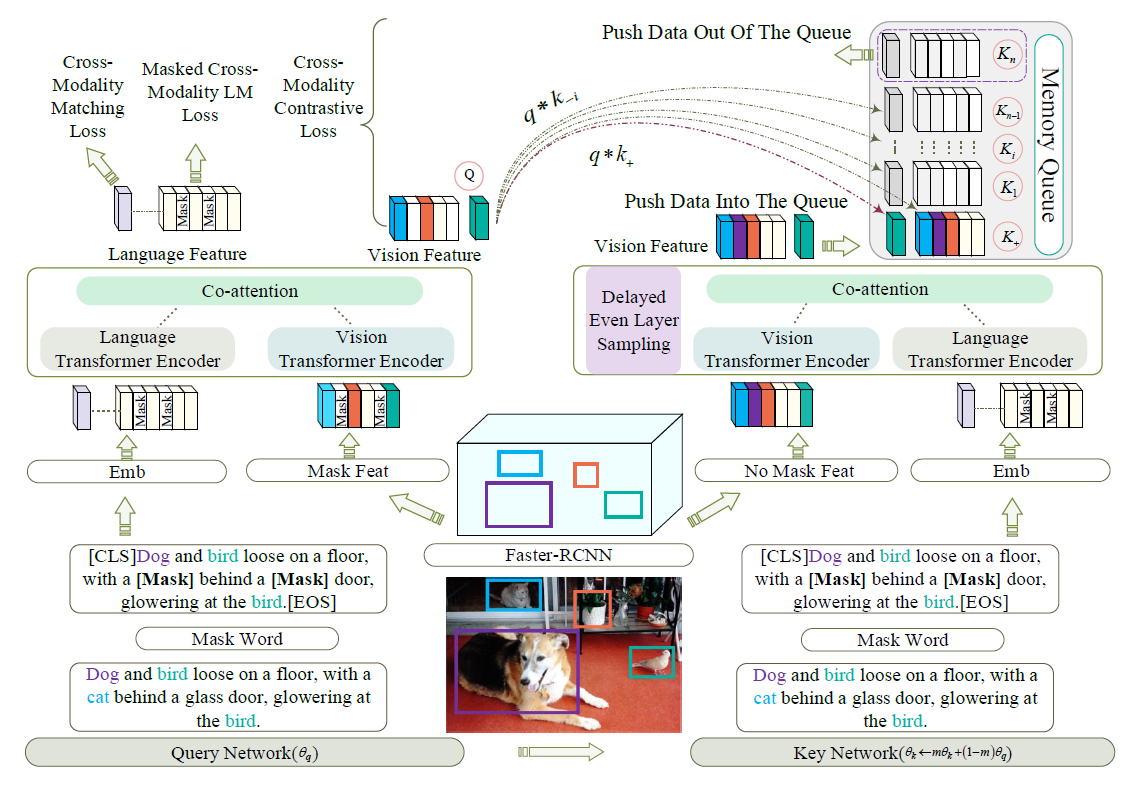
为VQA生成原因
想要在VQA任务中有突出的表现,model必须理解问题并找到问题相关答案的能力,有个严肃的问题是这些model在预测答案的时候到底能够理解image,question和answer到一个什么程度,它们是否只是利用了问题,图片或者答案中的biases
衡量模型对三个方面(questions, images, answers)的理解能力并不是一个主流工作,之前相关工作有对word进行微扰,检查视觉热力图等,文章希望做的是对三个方面做一个联合,同时测试模型语言和视觉模块
为了完成这一点,文章为VQA系统提出了一个novel task,不仅要理解问题(linguistic modality),理解图片(visual modality),同时也要为预测的答案提供理由,指出其和图片以及问题的关系
作者采用VCR(Visual Commonsense Reasoning)数据集,该数据集中包含图片,问题,对应的四个候选答案,和四个原因选项,作者用VQA系统选择答案,然后对答案生成原因,对比真实原因来评估model的综合理解能力
作者用这个方法测试了VCR领域领先的模型ViLBERT,随后将ViLBERT和语言模型GPT-2结合用end-to-end方式来预测答案和产生原因。idea就是将答案产生的原因loss反向传播到答案预测中,合理推断的注入能够提高模型的综合理解能力
本文方法
整体工作如图所示

过程分为两个部分:1. 计算预测答案的embedding $E_{A_p}$,2. 把$E_{A_p}$ feed到语言模块(预训练的GPT2)
Predicted Answer Embedding
文章采用模型ViLBERT,输入图像和问题,对于每个答案选项产生embedding,之后将embedding输入到softmax
因为选取最大概率的答案embedding会导致网络不可微,所以根据它们的softmax score对四个embedding进行加权平均
Generating Rationales
我们用条件语言生成的方式来产生理由,条件是之前生成的理由以及答案的embedding,求取最大对数似然,然后用VCR数据集来修正模型
实验
生成原因比较
ViLBERT-Fr:预训练VQA+ground-truth rationale调整的GPT-2
ViLBERT-Ra:文章中的模型(计算ViLBERT答案得分和答案embedding的softmax得分的KL散度)
结果说明原因生成模块能够帮助VQA模型理解问题
结果展示
人工裁定 (两个模型的理由哪个更佳)
![支付宝]() 支付宝
支付宝