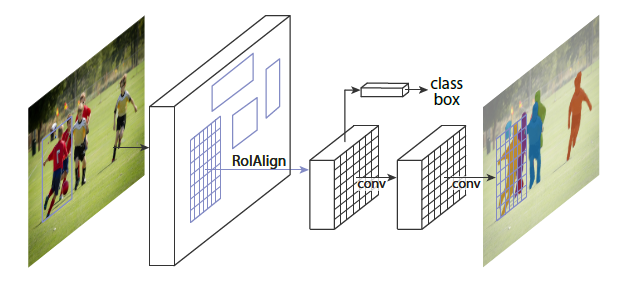
R-CNN:Region Proposal + CNN特征
RCNN第一次将CNN引入目标检测领域,相比之前(利用SIFT和HOG提取)将mAP提高30%以上,实现了53.3%的mAP
mAP指标
补充一下mAP指标的背景知识
mAP(mean Average Precision),字面意思,各类别 AP(检测精度) 的平均值
AP(某类别检测精度) 的计算方式则是P-R曲线下包围的面积(积分计算),P-R曲线的P指的是准确率(Precision),R指的是召回率(Recall),召回率也叫查全率
他们的计算公式分别为
$P=\frac{TP}{TP+FP}$
$R=\frac{TP}{len(GTs)}$
公式中的TP,FP含义如下
- TP(True Positive):IoU大于阈值的检测框数量(同一个GT(Ground Truth)的框只算一次)
- FP(False Positive):IoU小于等于阈值的检测框数量or同一个GT的多余检测框
IoU(Intersection of Union) 用于衡量预测框和真实框的贴合程度
$IoU_{A,B}=\frac{S_A \ \cap \ S_B}{S_A \ \cup \ S_B}$

R-CNN训练阶段
RCNN目标检测系统包含三个模块
- 生成区域候选框(region proposals)
- CNN提取特征
- 线性SVM分类
区域候选框搜索
用Selective Search搜索出2000个候选框
Selective Search算法主要思想:先将图片划分成许多的小区域,通过区域的相似度(颜色直方图,梯度直方图)按照区域从小到大聚合 (防止大区域不断吞并小区域),重复直到整张图像合并成一个区域,输出所有曾经存在过的区域作为候选区域框
这里得到的候选框是大小不一的,但是传入CNN提取特征的必须是大小一致的,所以这里需要对候选框进行处理
这里作者尝试了几种方法:
- 扩充到需要的规模大小 (B图)
- 用平均值在超出部分填充 (C图)
- 拉伸到对应尺寸 (D图)
结果是,先以padding=16扩充,然后进行拉伸效果最好
CNN特征提取
将候选区域数据缩放为$227 \times 227$,采用5个卷积层和2个连接层,从每个区域候选框中提取4096维向量
作者首先在ILSVRC2012数据集上进行了有监督的预训练(Supervised pre-training),然后微调(参数随机梯度下降)以进行域迁移(Domain-specific fine-tuning)
此外,还将CNN的ImageNet特定的1000路分类层替换为随机初始化的(N+1)路分类层(N个对象类+1背景)
训练过程中batchsize设置为128(正负样本32:96),将和GT框IoU大于等于0.5的标记为正样本(物体类别),小于0.5的标记为负样本(背景类别)
SVM分类器
对每个类别训练一个特定的SVM线性分类器,只有将物体全部包含在内的区域才被判定为正样本(区别于CNN的正样本),这里作者经过测试发现IOU阈值设置为0.3是最优的(小于这个值就标记为负样本)
Q1:为什么不直接用CNN分类(softmax本身不就起到分类作用么),而是在后面加个SVM分类器来画蛇添足
Q2:为什么SVM和CNN的正负样本定义不同
A:这两个问题其实是同一个问题,所以作者放在一起回答了,CNN容易过拟合,所以需要大量的训练数据,因此只能宽松标注条件,而SVM支持少样本训练所以阈值可以设置得低一些,同时因为CNN的宽松标注,导致其输出精度低,因此需要接SVM分类器
训练过程采用了标准的难负样本挖掘算法 (hard negative mining method)
难负样本挖掘算法
每次把那些顽固棘手的错误,送回去继续训练,直到成绩不再提升
R-CNN测试阶段
提取region proposals
将候选框归一化为227x227
对每个候选区域,用CNN提取特征
对每个类别用SVM分类器打分
用非极大值抑制(NMS)去除多余的框
将得分最高的bbox作为选定框
计算选定框与其它bbox的IoU,去除大于设定阈值的bbox
重复以上过程至待选集合为空
对bbox回归,见下
BBOX回归
作者通过误差分析,发现mAP低的原因是位置框不准确,于是提出一种简单的方法来提高mAP,用pool5层的数据来训练一个回归器,正则化设置$\lambda = 1000$,输出为xy方向的平移和缩放
在测试阶段对类别的位置框进行调整
RCNN的缺陷
- 速度过慢 (Selective Search,CNN需要对所有候选框提取特征)
- 内存占用大 (在过程中需要提取并保存每个候选区域)
- 非端到端 (需要分开训练不同模块)
![支付宝]() 支付宝
支付宝