SAAA [层叠注意力机制]
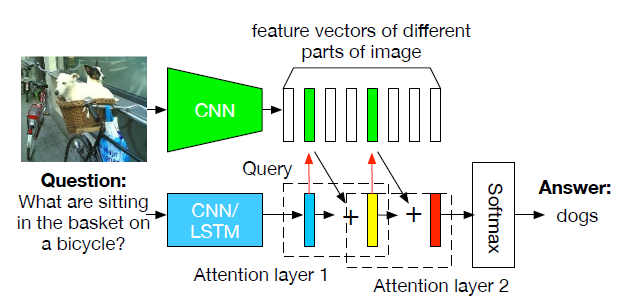
文章提出了一个相对简单的结构,经过精心的训练能达到SOTA,整体结构如图:

用LSTM对问题进行编码,用ResNet获取图片的特征,然后用soft attention计算multiple glimpses图像特征,最后进行分类
Method
Image embedding
用预训练的CNN来计算图片表示,作者使用的是ResNet,取最后一个池化层,得到的特征大小是14×14×2048维的,然后再对深度维度进行l2范数约束
Question embedding
将问题标记并嵌入到长度为p的向量中,然后用LSTM处理
Stacked attention
和SAN十分相似,计算图像特征空间维度上的多重注意力分布
每个图像特征的glimpse $x_c$是图像特征在所有空间位置的加权平均,注意力权值$a_{c,l}$对每个glimpse分别归一化,F是一个两层的卷积,共享第一层参数,仅依靠不同的初始化来产生不同的注意力分布
Classifier
最后将图像注意力和LSTM结果连接,输入到分类器(两层全连接层),损失函数为
Experiments
消融实验
VQA1.0上和SOTA的比较
VQA2.0上的表现
可视化展示
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 未央の童话镇!
打赏
![支付宝]() 支付宝
支付宝

相关推荐



评论
TwikooValine


