Causal TDE Inference [因果效应]
文章简介
场景图生成(SGG)——图像中对象和其关系的视觉检测任务,似乎从未真正实现其承诺:以一种全面的视觉场景表示支持高级任务的图推理,如视觉字幕和VQA

图中展示了SOTA模型的SGG结果,可以发现在几乎所有被检测到的物体之间的视觉关系大多是琐碎的,信息量也不大,如图c,在二维关系中除了near,has和on之外,我们所知甚少,这种严重偏见的生成来自于有偏见的训练数据,即存在长尾效应,因此,要执行合理的图推理需要区分出更细粒度的关系,比如将near替换成behind/in front of,将on替换成parking on/driving on
然而,我们不应该责怪有偏见的训练,因为我们的视觉世界本身和我们描述它的方式都是有偏见的:比如人带着包的情况总归是比狗带着包的情况要更多一些的(长尾理论 long-tail theory),对于人和桌子的关系,near的标注总比eating on要简单的多的(有限理性 bounded rationality),我们更喜欢说person on bike而不是person ride on bike(语言或表述偏见 language or reporting bias),事实上,大多数有偏见的注释可以帮助模型学习到良好的上下文检验,过滤掉不必要的搜索候选项,比如apple park on table和apple wear hat
对于机器和人来说,决策是内容(内因)和上下文(外因)的协作,在大多数SGG模型中,内容是主体和客体的视觉特征,上下文是主体-客体联合区域和成对对象类的视觉特征。而我们人类,在有偏见的天性中出生和成长,接受好的内容同时避免坏的,根据内容做出公正的决定,其内在机制是因果性的(causality-based),决定取决于内容主要的因果效应,而非语境的副作用,而机器通常是基于概率的(likelihood-based),预测相当于在一个巨大的可能性表中查找内容及其上下文,作者认为学习的关键是教会机器识别主影响和副作用
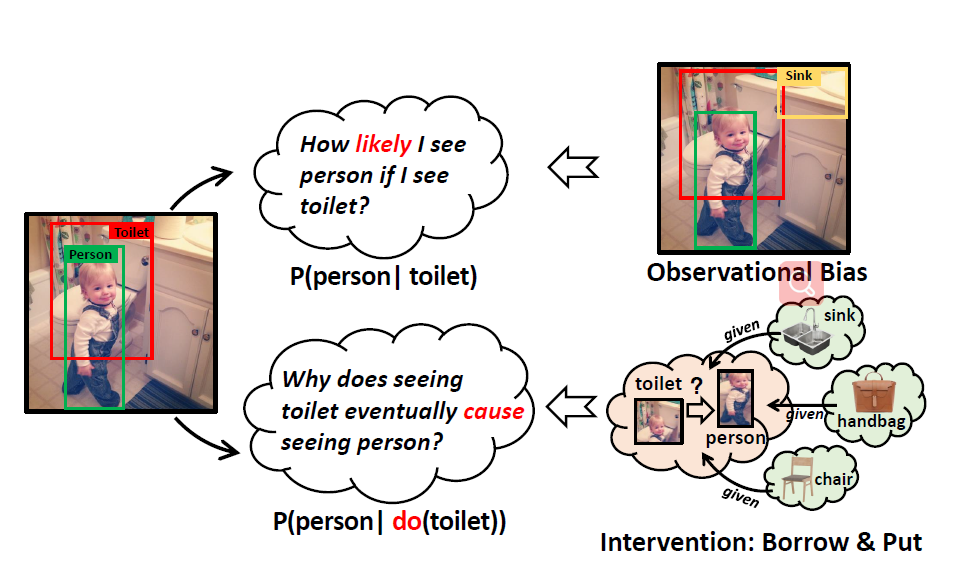
这篇文章中,作者建议赋予机器反事实因果的能力,以追求无偏预测当中的”主效应”:即如果我没有看到内容,我还会做出同样的预测吗
反事实存在于”I see”的事实和”I had not”的想象之间,事实和反事实的对比可以自然地移除内容的偏见,因为上下文是两个选项之间唯一没有改变的东西
为了更好地说明似然因果关系和反事实因果关系之间深刻而微妙的区别,举个简单的例子a dog standing on surfboard,如图所示,一个有偏见的训练会致使模型预测词on,请注意,尽管剩余的选择并不都是完全正确的,但由于这种偏见,它们仍然有助于过滤掉大量不合理的选择,为了更细致地观察它在语境偏差中的关系,作者在做的事情本质上就是在比较原始场景和反事实场景,消除dog和surfboard的视觉特征,而保持其它的视觉特征不动,这种做法可以专注于关系的主要视觉效果而不失去背景
作者提出了一种基于因果推理中全直接效应(TDE)分析框架的无偏SGG方法,下图中展示了事实和反事实两个场景的潜在因果图,更正式的介绍会在下文给出,现在可以简单地将节点理解为数据特性,将定向的链接理解为数据流
这些图提供了计算TDE的算法公式,准确地实现了反事实思维。提出的TDE显著改进了大多数谓词,并且,改进性能的分布不再是长尾的,这表明改进确实来自于提出的方法,而不是更好地利用了上下文偏差,TDE是一种与模型无关的预测策略,因此适用于各种模型和融合技巧
此外,作者提出了一个新的SGG框架,可以更全面地评估SGG,出了传统的评估方法,还包含了偏见敏感的方法:mean Recall,以及一种更全面图级别度量的句子到图的检索,在这个框架和几个主流的baseline下,作者验证了现有的模型存在严重的偏差,证明了无偏预测相比于其它去偏策略的有效性
相关工作
场景图生成
SGG在计算机视觉界受到越来越多的关注,这是由于其对于下游视觉推理任务可能带来的革命,大多数现有的方法都在努力寻找更好的特征提取网络,Zellers et al首先引入SGG的偏差问题,提出了无偏度量(mean Recall),但是他们的方法仍然局限于特征提取网络,使得有偏的SGG问题得不到解决,最相关的工作只是删除了训练集中那些显性且易于预测的关系
无偏训练
在机器学习中,偏见问题已经被研究了很久,现在的去偏方式大概可以分为三类:1.数据扩展或者重采样;2.通过精心设计的训练或者损失函数来实现无偏学习;3.从无偏表示中分离有偏表示。文章中提出的TDE输出第三类,主要区别在于TDE不需要训练额外的层来建模偏见,而是直接通过英国图上的反事实方法将偏见从现有模型中分离出来
干预分析
干预分析又被称为效应分析,广泛应用在医学,政治,或心理研究,作为研究某些治疗或政策效果的工具,然而,多年来它一直被计算机视觉界所忽视。最近很少有研究试图赋予模型因果推理的能力
因果图中的有偏训练模型
作者在下图中以因果图的形式总结了SGG框架,这是一个有向无环图,说明一组变量如何通过因果关系相互作用,它揭示了因果关系背后的数据和变量如何获得他们的值
在操纵节点值和修剪因果图进行反事实分析之前,我们首先在图形视图中回顾传统的有偏见的SGG模型训练
图(b)中的因果图适用于各种SGG方法,因为它是高度通用的,对具体的实现没有限制,我们来研究三个有代表性的模型公式:传统的VTreansE,SOTA模型MOTIFS以及VC-Tree,用节点和链接来表示
Node I(Input Image & Backbone):一个预训练的Faster R-CNN被固定在这个节点,其输出了bbox的集合以及图片I的特征图M
Link I $\to$ X(Object Feature Extractor):其首先提取ROI特征,以及暂定的对象标签L,然后像MOTIFS或VCTree一样,可以使用以下模块为每个对象编码视觉上下文
MOTIFS用BiLSTM来实现而VCTree采用BiTreeLSTM,而早期工作诸如VtransE则简单地采用了全连接层
Node X(Object Feature):成对的对象特性X从每对x中获取值,作者将i和j表示的组合表示为下标e:$x_e=(x_i,x_j)$
Link X $\to$ Z(Object Classification):每个对象的微调标签通过$x_i$计算:
MOTIFS和VCTree采用LSTM和TreeLSTM作为解码器来捕捉对象标签的同现性,每个LSTM/TreeLSTM单元格的输入是特征和前面的标签的连接,而VTransE则使用常规的全连接层作为分类器
Node Z(Object Class):包含了一对独享标签的独热编码:$z_e=(z_i,z_j)$
Link X -> Y(Object Feature Input for SGG):对于关系分类,两两特征X由以下模块合并为联合表示:
同样,MOTIFS和VCTree在这一步采用了Bi-LSTM和Bi-TreeLSTM,然后连接这对对象特征,VTransE则采用全连接层和元素级减法来完成特征合并
Link Z $\to$ Y(Object Class Input for SGG):在该链接中通过联合嵌入层计算语言先验$z_e’=W_z[z_i\otimes z_j]$,其中$\otims$为每对对象标签产生独热编码R
Link I $\to$ Y(Visual Context Input for SGG):此链接提取上下文联合区域特征 $v_e’=Convs(RoIAlign(M,b_i\cup b_j))$,其中$b_i\cup b_j$表示两个RoI的合并box
Node Y(Predicate Classification):最终的预测结果logits Y由三个分支的输入通过一个融合函数得到
Training Loss:所有的模型都使用了传统的目标标签和谓词标签的交叉熵损失进行训练,为了避免任何单一的链接自发地支配了logit $y_e$的生成,特别是$Z \to Y$,我们进一步增加了辅助交叉熵损失,单独预测每个分支的$y_e$
因果效应的无偏预测
一旦完成上述训练,就可以通过模型参数了解变量之间的因果依赖关系,传统的偏见预测只能看到图像整个图像的输出,不知道特定的一对对象如何影响它们的谓词,因果推理鼓励跳出黑盒子去思考,从图形的角度看,不再需要将整个图形作为一个整体,我们可以在因果图上操作几个节点,看看会发生什么,比如切断链接I $\to$ X,并对X指定一个虚拟值,然后观察谓词是什么,上述操作被称为因果推理中的干预,接下来,我们将通过干预及其诱导的反事实来进行无偏见的预测
标记
干预:可以表示为$do(\cdot)$,它删除变量的所有输入链接,并要求变量取某个值,$do(X=x)$表示X不再受其因果父母影响
反事实:意思是”与事实相反”,并进一步赋予变量”世界冲突”的值组合,比如在X上执行了干预$do(X=\bar{x})$,Z依旧采取原来的z值就像x时一样
因果效应:使用pairwise对象特性X作为进行干预的控制变量,目的是评估其效果,如果这对对象不存在,则不存在任何有效关系,观测到的X记为x,干预未见值记为$\bar{x}$,设置为训练集的平均值或是零向量
在执行干预$X=\bar{x}$之后,logits Y可以计算为
u是SGG的输入图片,按照上面的符号,原来的和反事实的Y被记为$Y_x(u)$和$Y_{x,z}(u)$
总直接影响(DTE)
与趋向于有偏见的静态似然不同,无偏见的预测于观察结果$Y_x(u)$和其相反的替代结果$Y_{x,z}(u)$之间的差异,后者是我们想要从预测中去除的特定背景偏差。直观上讲,我们所追求的无偏预测是从空白到观察到的具有特定属性,状态和行为的真实物体的视觉刺激,而不仅仅是来自环境和语言先验,这些物体的特定视觉线索是更细粒度的,信息更客观的预测的关键,因为即使整个预测偏向于dog on surfboard,”straight legs”会使得standing on比sitting on更具说服力,在因果推断中,上述预测过程可以被计算为总直接效应(TDE):
第一项来自原图,第二项来自反事实
注意到这里还有另一项影响,总影响(TE),容易和TDE混淆,TE并不像TDE一样推导反事实的偏见$Y_{x,z}(u)$,TE允许X所有的子节点通过干预$do(X=x)$改变,因此TE可以表示为
主要差别是$Y_{\bar{x}}(u)$不受原对象标签的限制,所以TE仅取出了数据集中的一般偏见,而不是我们所关心的干预导致的特定偏见
最后,用TDE来替代传统的一次预测,本质上是二次思考,得到无偏预测
实验
实验采用Visual Genome (VG)数据集,测试了三个model:VTransE,MOTIFS和VCTree,以及两种融合方法SUM和GATE,所有模型共享相同的超参数和预训练检测器模型
文中提出的SGG框架有三种评价方式:
Relationship Retrieval (RR):这个评价可以被分为三个子任务:(1)Predicate Classification (PredCls): 以GT的bbox和表现作为输入;(2)Scene Graph Classification (SGCls):使用没有标签的bbox;(3)Scene Graph Detection(SGDet):从零开始检测SGs,RR的传统评价方法是Recall@K(R@K),由于存在报道偏见,被本文所弃用,为了有价值的”tail”而非微不足道的”head”,本文采用了mean Recall@K(mR@K),mR@K分别检索每个谓词,然后对所有谓词的R@K取平均值
Zero-Shot Relationship Retrieval (ZSRR):ZSRR和RR有三个相同的sub-tasks
Sentence-to-Graph Retrieval (S2GR):该算法利用图像标题作为查询语句,检索以SGs表示的图像,RR和ZSRR都是三级评价,忽略看图形级的一致性,因此,作者设计了S2GR,使用人类描述检索SGs,作者并没有使用图像字幕和VQA这样的代理视觉语言任务,因为他们的实现有太多和SGG无关的组件,且数据集受到自身偏见的挑战,在S2GR中,检测到的SGs(使用将SGDet)作为图像的唯一表示,切断了对黑盒视觉特征的所有依赖,对SGG的任何偏差都会敏感地破坏SGs的相干性,导致检索结果较差,举个例子,如果walking on被检测为偏见选项on,则图片会和sitting on以及laying on的图片混淆
实验结果
可视化结果
![支付宝]() 支付宝
支付宝