seada-VQA [对抗数据扩充样本]
Introduction
最近的研究表明VQA的性能取决于训练数据的数量,已有的算法总是能从更多的训练数据中受益,这意味着不需要手工标注便能进行数据扩充,从而提升VQA的性能
现有的数据增强方法通过数据扭曲(data warping)或过采样(oversampling)来扩大训练数据集的大小,数据扭曲转换数据并保留其标注,方法包括几何和颜色变换、随机擦除、对抗性训练和风格迁移,过采样生成合成实例并将其添加到训练集中,数据增强可以有效地缓解DNN的过拟合问题
然而在VQA问题上少有对数据增强的研究,因为数据增强的同时需要保持[答案|问题|图像]三元组的正确性,几何变换和随机擦除都难以维持答案的正确性,在文本方面,提出语言转换的通用规则也是很有挑战性的
先前的工作都是基于已知的图像和给出的答案来产生合理的问题,即视觉问题生成,但是这种方法会生成一些奇怪的句子或者存在语法错误,而且生成的数据是从相同分布的原始数据中提取的,并不能减轻过拟合
作者将视觉数据和文本数据作为扩充数据生成语义等价的对抗数据,视觉对抗样本是基于梯度的非目标的attacker生成的,文本对抗样本能够欺骗VQA模型(预测错误答案)同时保持问题等效性,对抗性实例的存在不仅表明了卷积网络的泛化能力有限,而且对这些模型的实际部署也构成了安全威胁
作者对BUTD在VQAv2上进行对抗性训练,采用纯样本(clean examples)和即时生成(on-the-fly)的对抗样本,实验结果表明,作者提出的对抗训练框架不仅比其他数据增强技术更好地提高了模型在纯样本上的性能,同时提高了模型对对抗攻击的鲁棒性,作者是VQA领域第一个同时对图片和文本做数据增强的
文章的贡献概括如下:
- 作者提出生成视觉和文本的对抗式样本来扩充VQA数据集,生成的数据保留了语义,探索了学习到的决策边界,可以帮助提高模型的泛化能力
- 提出了一个对抗训练方案,使VQA模型能够从对抗样本的正则化中受益
- 用作者的方法训练的模型在纯验证集上达到了65.16%的准确率,比普通训练高出1.84%,此外,经过对抗训练的模型在对抗样本上提升了21.55%
Related Work
VQA目前研究方法包括注意力,合成方法和双线性池化,相当一部分的VQA最新的算法都是在BUTD注意力机制上建立的,因此作者也选择了BUTD作为baseline,研究侧重点在数据增强上
在分类问题上对于文本增强只有少量工作,在VQA上已有的数据增强的研究都是单模态的,且严重依赖复杂的模块来实现轻微的性能提升
近年有工作在图像中增加噪声生成对抗样本来评估DNN的鲁棒性,在NLP领域,最先进的文本DNN attacker采用不同于视觉领域的方法来生成文本的对抗样本,作者的灵感主要来源于SCPNs和SEA。研究表明,即使在ImageNet上,通过精心设计的训练方案,对抗性训练也可以提高模型的性能。一些在VQA上进行对抗攻击的工作仅仅对图片进行了攻击,但并没有讨论杜康样本对VQA模型的作用,总而言之,对抗样本如何促进VQA仍然是一个待解决的问题
Method
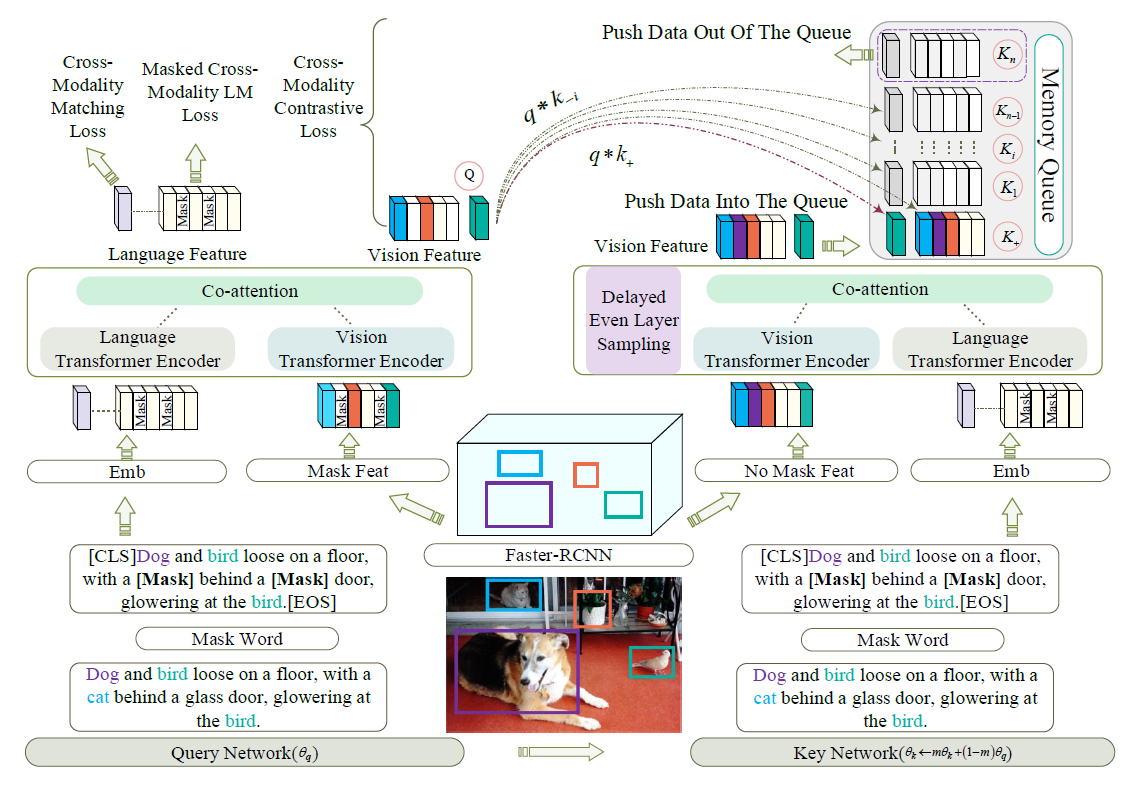
模型的框架如图所示

首先产生文本的变体并保存,随后生成即时的视觉对抗样本,获得语义相等的三元组,然后用他们进行对抗训练
VQA model
VQA问题可以表述为根据参数概率测度预测给定图像v和问题q的答案a的问题
$\theta$是所有要学习的参数,$A$是所有的答案,作者采用BUTD作为模型的骨干
Data Augmentation
由于存在影响答案的风险,作者避免直接地操作原始输入,比如裁剪图像或者改变词序,受对抗性攻击和防御的启发,作者提出生成对抗性样本作为额外的训练数据
Visual Adversarial Examples Generation
对抗性攻击起源于计算机视觉界,本质上是对图像增加扰动使得输出错误的答案,作者采用了一个高效的基于梯度的attacker IFGSM来生成视觉对抗样本,首先介绍一下FGSM,因为IFGSM是其的一个扩展,其过程表示为
$v_{adv}$就是$v$的一个对抗样本,$\theta$是模型参数,$L(\theta,v,q,a_{true})$表示VQA训练的代价函数,攻击将梯度反向传播到输入的视觉特征进行计算$\nabla_vL(\theta,v,q,a_{true})$,然后在$sign(\nabla_vL(\theta,v,q,a_{true}))$方向上小步调整输入使得loss最大化
IFGSM就是多次执行上述过程
$Clip_{v,c}(A)$表示对$A$的元素级裁剪,$A_{i,j}$被裁剪到范围$[v_{i,j}-e,v_{i,j}+e]$,$\alpha$是每一次的步长,作者将这个过程记为$VAdvGen(v,q)$
Semantic Equivalent Questions Generation
由于文本是离散的,所以不能直接采用图像DNN的攻击方法来生成一个问题的对抗样本$q_{adv}$,文本中的微小变化,如字符或单词的变化,很容易破坏语法和语义,造成攻击失败,遵循不改变输入数据语义的原则,作者使用序列到序列的意译模型(paraphrasing model)生成语义上等价的对抗式问题
作者提出了一个完全基于神经网络的转述模型,它是对基本的encoder-decoder Neural Machine Translation(NMT)框架的扩展,encoder(RNN)将原句的意思压缩成一个向量序列,decoder(条件RNN模型)逐词生成目标句子,模型的损失函数采用softmax
生成结果如图所示,括号内是一致性得分
生成的语句可以轻易地使BUTD犯错,作者观察到$q_{adv}$不仅从正确的预测到错误的预测,而且在某些情况下将错误的预测更正为正确的预测,这表明模型决策是弱对抗的,模型在进行预测时利用了假相关性
Adversarial Training with Augmented Examples
作者将对抗样本作为额外的训练样本,并用对抗样本和纯净样本的混合集来训练网络,问题的扩充与模型无关,在训练前生成,而视觉对抗性样本在训练的每一步都不断生成,根据问题输入的不同,有两种视觉上的对抗样本
于是可以产生四个训练对$(v_{qc},q)$, $(v_{qadv},q)$,$(v_{qc},q_{adv})$以及 $(v_{qadv},q_{adv})$,所有的对语义都是相等的,也就是说拥有相同的GT答案
所以loss被计算为
整个对抗训练过程为
Experiment
消融实验
在不同training set大小下的作用
![支付宝]() 支付宝
支付宝