FPAIT [小样本学习]
INTRODUCTION
构建一个具有人类智慧的AI系统是一个非常大的挑战,这样的AI系统需要具有的其中一个重要的能力是从少量的样本中快速学习到新的内容,特别是多模态场景。最近有很多关于图片或者语言的小样本学习(few-shot)的尝试,但是很少在多模态问题上做小样本学习,这需要同时利用好图片和语义知识。在多模态场景下的小样本学习更具现实意义,比如,亚马逊每周会推出数千件新产品,这些产品在描述和新产品图片中都包含了不常见的词语,共同了解图片/文字及其关系,比只关注图片或文字更能更好地向客户推荐这些新产品
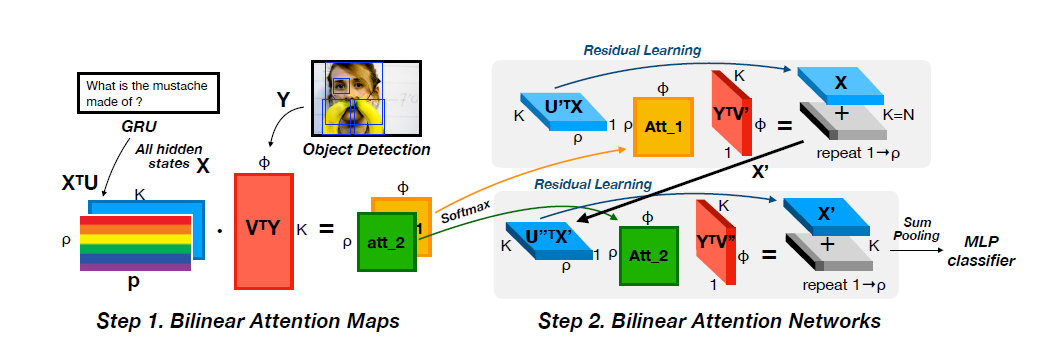
在本文中,作者从小样本图像字幕和VQA两个方面来研究小样本多模态学习,图像字幕和VQA的示例如图所示

对于这两个任务,现有的算法大多集中在监督学习上,因此需要大量的人工标注的图像文本对来进行训练,由于一些单词在少数场景中是不常见的,甚至不曾出现,这些监督算法不能很好地处理这些新单词。现在有一些关于图像字幕和VQA的新出现对象的研究,它们通常利用包含新单词的大型外部文本数据库来学习文本表示。这样,他们的文本模型可以理解新单词,即使这些单词不在训练图像-文本对中
相比之下,小样本学习更加困难,因为新的目标对象或单词不能以任何形式出现在训练数据中,这样一来,他们的文本模型就难以学习到新单词的更好的表示,从而导致性能下降,因此现有的算法不适合小样本的图像字幕或者VQA学习
作者提出了图像文字模型的快速参数适应方法(FPAIT),以解决小样本问题,FPAIT的主要思想是知道图片文字联合学习器如何去学习,传统算法的核心思想是学习一个模型来拟合数据,FPAIT则指导模型如何在新的任务中只用少量样本更好更快地泛化,具体来说,FPAIT通过几个例子,对联合的图像-文本学习器进行大量不同的视觉语言任务训练(如图所示),FPAIT是为了获得良好的图像-文本联合学习器的初始参数,使其通过几个更新步骤就能最大限度地提高新任务的性能
由于该初始化是从多个不同的任务中训练出来的,因此该模型的内部表示应该适合于各种任务,即具有良好的泛化性,因此,FPAIT在新的任务上只需要很少的微调步骤就可以取得很好的效果
现有的算法通常使用最先进的cnn对图像特征进行编码,这些CNN模型需要大量的训练数据才能保证良好的性能,但是,在本文的设置中,一个任务可能只有5个训练样例,因此,这样小的训练数据会引入大的bias,这对CNN模型是有害的,为了克服训练数据小的影响,FPAIT引入了对图像特征的动态线性变换,这些线性变换被整合到CNN模型中来缩放和移动中间特征,这样bias能够得到减缓,此外,这些线性变换的参数是由经过编码的文本特征生成的,这样文本数据就可以有效地影响图像特征,实验表明,所提出的FPAIT新架构优于典型的图像和文本嵌入方法
本文的贡献有
提出FPAIT来处理小样本图案品字幕和VQA,经过FPAIT训练的模型可以在少量样本的情况下快速对新任务做出自适应
提出了一种先进的神经网络来完成图像文本对小样本学习的任务,该网络从文本数据中生成动态参数,并利用这些参数有效地影响图像编码
FPAIT在图像字幕和VQA任务中取得了很好的效果
RELATEDWORK
图像字幕相关的内容略过
Visual Question Answering
VQA模型的关键是如何结合图像和文本内容,传统的对问题和图像得到联合嵌入的方法需要大量的监督学习,因此不适合小样本的研究
为了解决VQA中新出现对象的问题,采用的方法一般是引入外部知识库,而作者提出了一个更困难的设置,即新概念不能出现在任何预训练数据中,Teney et al提出了基于相似的元学习方法来完成小样本VQA学习,他们只在小型的只包含七类问题的VQA-Number数据集上评估算法,他们在大规模数据集上缺乏有效的证据
Few-shot learning
现有的优化算法需要大量标记数据来更新深度cnn。因此,当仅有少量的训练实例可用时,它们的表现很差,少量示例学习(few-examples learning)允许使用未标记数据,而小样本学习(few-shot learning)则不能。在本文中,关注的是小样本学习设置
这里有几种值得注意的小样本学习方法,Munkhdalai et al研究了针对小样本分类模型的复杂权值更新方案,Finn et al约束元学习器使用普通的梯度下降更新基础学习器,作者主要follow第二篇,而与之不同的是,作者采用图片文本对作为输入而非单纯的图片。此外,为了克服多模态场景中小样本训练的副作用,作者利用文本特征生成动态参数来自动对图像特征进行归一化
METHODOLOGY
FPAIT的思路源于元学习和条件归一化,元学习通常关注于小样本的图像分类,而FPAIT将其扩展到图像和文本的联合建模,并且FPAIT通过条件归一化来克服模型中的少量样本导致的bias
Preliminary
将VQA问题中的图片记为$I$,问题记为$Q$,生成自然语言答案的函数记为$f$,设有$C$种不同种类的答案,函数f可以是一个神经网络,它将Q和I映射到C个候选答案的置信度分数,$p = f(Q, I)$,$p \in R^c$表示置信度分数,大多数现有的算法通常以$y=argmax_ip_i$作为最终的预测
大多数图像字幕或VQA方法通过最大化正确答案或空词的可能性来学习f的参数的
其中$i$为训练数据的下标,$P$为条件概率,为了对性能进行评价,$f_{\theta}$对每个测试数据进行反馈,得到预测的结果或描述,通过一些评价指标来计算评价性能
Fast Parameter Adaptation
区别于传统的步骤 (上文那个式子),作者采用的是元学习的步骤,要求学习模型能够在来自p(T)的不同任务样本上取得良好的性能,而不仅是传统设置的单个任务,如果few-shot是K-shot N-way的话,那么一共就需要K×N个样本,为了解决这个元学习问题,FPAIT学习了一个良好的初始化值$f_{\theta}$,以便能够快速适应从p(T)中采样的不同任务,经过训练的联合文本图像学习器$f_{theta}$应该根据这K个训练样本快速调整其参数,然后对T中的新样本进行良好的推广,当$f_{\theta}$适应了特性的T时,作者在这个T中采样新例子对f进行评估
将参数设为$\theta$,适应后的参数设为$\theta’$,假设使用基本随机梯度下降的一次梯度更新来进行参数自适应,计算参数的式子为
这里使用一个梯度步骤来简化符号,而参数适应算法Opt还可以使用SGD或Adam的多个梯度步骤
元学习的过程如图所示
目标函数为
FPAIT Architecture and Algorithm
编码图片的CNN包含四个卷积块,每个卷积块包含一个$3\times 3$的卷积层和一个BN层以及ReLU激活,特征通道分别为64,96,128和256,在前三个卷积块之后,有三个池化层,步长为2,在最后一个卷积块之后有一个全局池化层,最后得到的是一个256维的向量
问题则被编码为512维的特征向量
传统的特征融合方式如图(a)所示,这种模型需要大量的数据来训练,由于训练样例少而引入的模型偏差大,会影响性能,此外,在多模态场景中,模型不仅要学习图像/文本信息,还要学习它们之间的关系,此时模型偏差问题变得更加严重,为了缓解小样本多模态场景中的模型偏置问题,作者采用了一个带有动态参数的变换函数
对于这个变换函数,可以由多种选择,比如卷积层或全连接层,作者在文章中采用了Channel-wise Linear
Transformation(CLT),设文本编码器为g,将文本Q作为输入产生文本特征g(Q),对于CNN中第c层的特征,CLT的参数$\gamma_c$和$\beta_c$为
$g_\gamma$和$g_\beta$为全连接层,$F_c$表示CNN第c层的输出,$\gamma_c$和$\beta_c$为两个向量,维数和$F_c$的通道数相同,如图(b)所示,在每个bn层后接CLT
答案预测则是使用了三层的MLP,前两层输出维度为512,最后一层输出每个答案的概率
损失函数为$f(I,Q)$和GT之间的交叉熵损失
这里采用了一个非常简单的CNN,没有用复杂的CNN,比如resnet-101,这是因为复杂的CNN容易过拟合
EXPERIMENTAL EVALUATION
在Toronto COCO-QA上的比较
定量分析
![支付宝]() 支付宝
支付宝