CSS-VQA [反事实]
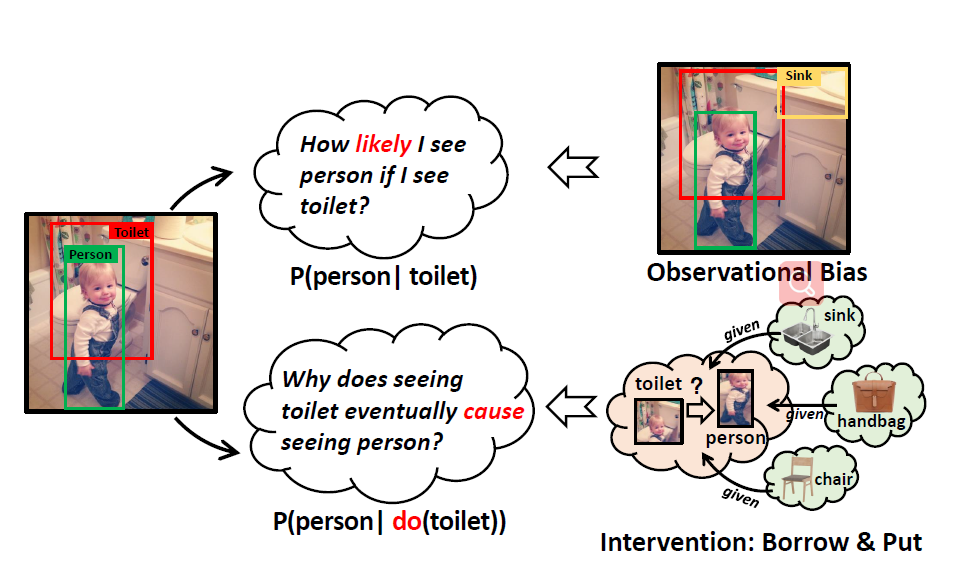
由于数据集的问题,目前很多VQA模型仍然过于依赖language biases,比如一个对于”how many X”问题只会回答2的模型可以依然得到比较满意的表现。因此有了新的判断指标VQA-CP (VQA under Changing Priors),这个数据集中训练集和测试集的QA分布不同,导致许多SOTA的VQA model在这个数据集中准确率都有显著的下降
当下流行一些基于集成(ensemble-based)的方法来减轻bias的影响,他们用question-only model来调整VQA model的训练过程,这些方法大致可以分为两类:
1.adversary-based:用对抗的方法训练两个model,最小化VQA model的损失的同时最大化question-only model的损失,两个model共享同一个question encoder,目标是学习一个bias-neutral的问题表示。然而,因为训练过程不稳定,因此产生了巨大的噪声
2.fusion-based:最后将两个model的答案分布结合起来,设计理念是让VQA model更关注那些question-only model所不能回答的问题尽管这些ensemble-based方法在VQA-CP上取得了很好的表现,但是作者认为他们仍不能铸就一个理想的VQA模型
作者认为,一个理想的VQA模型应该有两个不可缺的特点:1)视觉可解释性(visual-explainable):模型做决定需要依赖于正确的视觉区域;2)问题敏感性(question-sensitive):要能够敏锐地察觉到问题的变化并作出反应

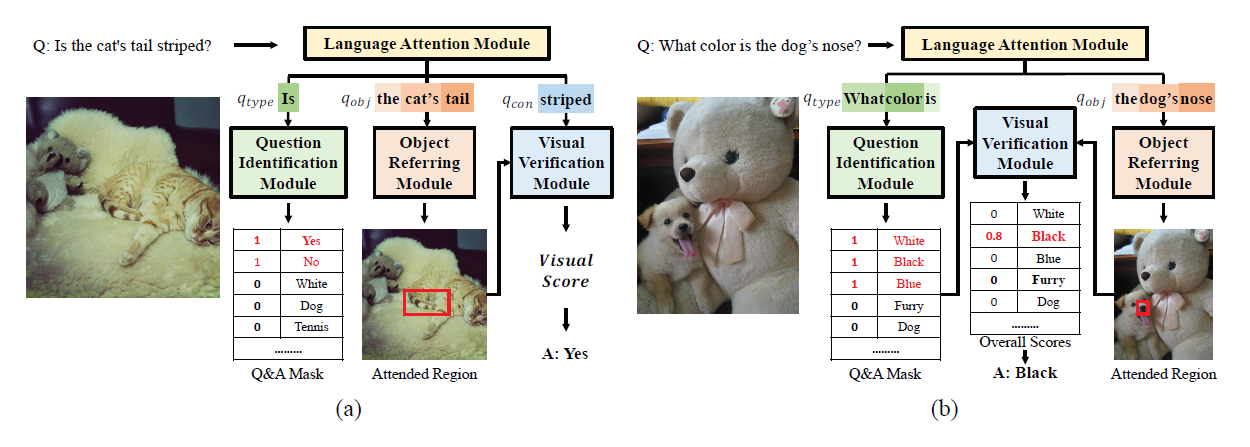
文章提出了Counterfactual Samples Synthesizing (CSS)训练方法,这是一种通用的方法,可以和现有的VQA模型结合,CSS包含两种样本整合方式:V-CSS和Q-CSS,V-CSS更改图片中回答问题的关键因素并和问题构成新的QA,Q-CSS则更改问题中的关键词和原图片构成新的QA。同时为了避免高昂的人工标注代价,作者提出一种动态的答案生成方法来近似得到答案,比如not green。然后用原数据和整合数据结合训练,使VQA models更加关注标注的词或者对象
相关工作
VQA中的language biases
消除VQA中的language biases有两种方法,一种是平衡数据集来减少biases,比如VQA-CP,另一种是设计模型来减少biases,比如ensemble-based methods
VQA视觉可解释性
早期工作中为提高VQA的视觉可解释性,通常用人类注意力作为监督来引导model的注意力,然而因为存在强biases,就算拥有合理的注意力图,model仍然会无视图中的信息。近期一些研究用Grad-CAM来观察每个对象对正确答案的贡献,然而这些模型有两个问题,一是需要额外的人工标注,二是训练并不是end-to-end
VQA问题敏感性
如果VQA系统真的理解了问题,那么他们应该对问题细微之处的变化敏感。目前只有一项工作研究了语言变化对VQA的影响[1],但这项工作中只考虑VQA系统对于问题句式的变化的稳定性,作者认为还需要让系统察觉到关键词替换时问题的不同之处
[1] Meet Shah, Xinlei Chen, Marcus Rohrbach, and Devi Parikh.Cycle-consistency for robust visual question answering. In CVPR, 2019.
VQA的反事实训练样本
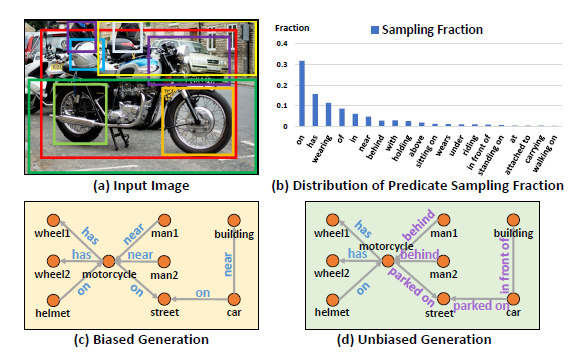
一些研究也在尝试生成VQA的反事实训练样本,但是这些工作基本上采用GAN来生成图片,而CSS仅仅是标记关键目标或者关键词,更为简单和泛用
文章贡献
CSS训练方法
训练分为三个主要步骤:
1.用原样本$(I,Q,a)$来训练模型;
2.生成反事实样本$(I^-,Q,a^-)$以及$(I,Q^-,a^-)$;
3.用反事实样本训练模型
V-CSS
1.最初目标选择(IO_SEL),选取和QA高度相关的目标,方法follow[2]
2.目标贡献计算,计算每个目标对正确答案的贡献,follow了三篇使用modified Grad-CAM的文章,核心计算公式为
3.关键目标选择(CO_SEL),选取目标top K作为关键目标,将其mask为$I^-$,剩余目标mask为$I^+$
4.动态答案生成(DA_ASS)
利用$I^+$生成对应的$a^-$
[2] Jialin Wu and Raymond J Mooney. Self-critical reasoning for robust visual question answering. In NeurIPS, 2019.
Q-CSS
1.关键词贡献计算,和V-CSS中贡献计算类似
2.关键词选择(CW_SEL),首先提取问题种类相关的词(比如What Color),选取除了问题种类相关的词外的top-K作为关键词,将这些词用特殊的标记[MASK]来替换得到$Q^-$,将除了关键词和问题种类相关的词外的词用特殊标记[MASK]替代得到$Q^+$
3.动态答案生成(DA_ASS),同V-CSS
实验结果
各种模型和加上文章方法后的对比
实验结果展示
![支付宝]() 支付宝
支付宝